Part 1: Testing with actual k-means and 3 agentsDuring this testing, each agent is only processing the features that belong to it (determined by distances from features to its k-means label). Because the video is 7 seconds, there are 7 images. Initially:
Here are the numbers of matches broken down to each agent for each image:  Testing runtime:  Part 2: Parameterize video processing functionalityThree additional ROS parameters are added to the configuration file: data_format, video_extraction_frame_rate and absolute_video_path. Now the user can specify whether to input data from images or a video, what is the extraction frame rate, as well as the location of the target video all in the ROS parameter file. All parameters have been tested. They are working correctly. Part 3: Documentations and more
0 Comments
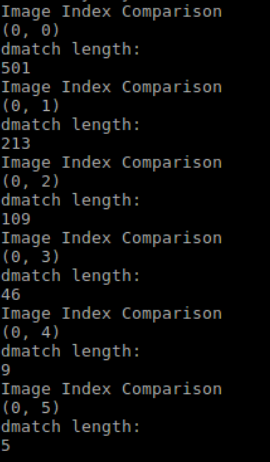
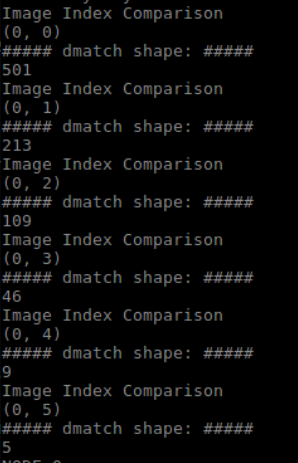
Part 1: New functionality & DebuggingThe previous version uses images in a folder to extract features. Now the new version can process any saved video files. It reads one image from the video each second (read rate can be specified), and then passes the images to the Distributed QuickMatch System for processing. The video read functionality is added on top of the image read functionality. It is written in a different function, so the user can switch between the new get_images_from_video function and the old get_images function. Distributed QuickMatch initially was not working after I added the new video read functionality. I spent a few hours debugging and found that in the calc_density function, I passed in the number of features as the last argument when I am supposed to pass in the number of images. After the correction, everything works correctly. Part II: Testing results for video processingSince previous testing data only includes images, I took a new video to use for testing. You can find the original 7 seconds video here. Below are the 7 images outputted by the algorithm: (Note: these are the results of the debugging mode, meaning k-means is not actually computed/one node gets all the features)  Figure 1: Image 1 vs Image1  Figure 2: Image 1 vs Image2  Figure 3: Image 1 vs Image 3  Figure 4: Image 1 vs Image 4  Figure 5: Image 1 vs Image 5  Figure 6: Image 1 vs Image 6  Figure 7: Image 1 vs Image 7 Nest Steps:There are still some leftover stuff to be done. Since next week is the last week, I'll finish the following and conclude the the project:
Part I: DocumentationThe Documentation has been completed here. Part II: QuickMatch RuntimeWith 3 agents running (6 ROS nodes since each agent has a feature node and a quickmatch node) and each agent processing 6 images of size 1008 x 756, the QuickMatch Runtime is as follows:
The total end-to-end runtime (from starting reading image to finishing QuickMatch) is as follows:
Part III: Dealing with video processingIf we are dealing with a recorded videos, we can easily convert videos to images based on a certain frame rate, and then run the existing algorithm on the extracted images. I've found tutorials of how to do that in openCV (https://medium.com/@iKhushPatel/convert-video-to-images-images-to-video-using-opencv-python-db27a128a481) so this is definitely possible. If we are dealing with live videos, there's a ROS package called video_stream_opencv that enables a camera to publish a stream of ROS images. Here is the official ROS page and here is the GitHub page. QuestionI have roughly looked over Zack's NetMatch code (QuickMatch with contested points), but I have not looked deeply into it. It seems like there is a good amount of code that I need to read in order to understand what exactly is going on. Given the amount of time left this semester, I feel that I would not have enough time to finish implementing it in the distributed version and debugging.
I will work until the last day of final exam (May 9), which means I have two more weeks to work on things. So the question is: Should I work on a version with contested points or a version of analyzing recorded video frames? I am more confident that I will have the recorded video frames incorporated into the existing code in the next 2 weeks, but I will work on the contested points if that is of higher priority. Part 1: Debugging FinishedAll the debugging has been finished. The current code works correctly. Regarding the bug from last week, I have added another field in the custom ROS message to transmit keypoints extracted during feature extraction. Since ROS does not support object publishing, I extraced [float x, float y, float size] from the 'cv2.keypoint' object and published them as an array of floats for each feature. They are transmitted from the original node where features are extracted, all the way to quickmatch_node where the graphing occurs after quickmatch algorithm is run. The 'cv2.keypoint' objects are rebuilt using the received data in the 'quickmatch_node.py', and the objects are using for graphing. Part 2: Result comparison with centralized codeThe following screenshots show that the result of the distributed QuickMatch is exactly the same as the result of the centralized QuickMatch (Figure 1 - 6).   Figure 1: Centralized result (above) and distributed result (below) on image 1.   Figure 2: Centralized result (above) and distributed result (below) on image 1 and 2.   Figure 3: Centralized result (above) and distributed result (below) on image 1 and 3.   Figure 4: Centralized result (above) and distributed result (below) on image 1 and 4.   Figure 5: Centralized result (above) and distributed result (below) on image 1 and 5.   Figure 6: Centralized result (above) and distributed result (below) on image 1 and 6. Part 3: Distributed results on new images takenSince the results of the distributed version have matched the ones from the centralized version, I ran the distributed version on the 6 new images I took before I left the lab due to the pandemic. The results are shown below (Figure 7 - 12).  Figure 7: Results from the distributed version on new image 1.  Figure 8: Results from the distributed version on new image 1 and 2.  Figure 9: Results from the distributed version on new image 1 and 3.  Figure 10: Results from the distributed version on new image 1 and 4.  Figure 11: Results from the distributed version on new image 1 and 5.  Figure 12: Results from the distributed version on new image 1 and 6. Part 4: Distributed results on new images taken with true k-meansIn order to debug, k-means has been set to the mean feature vector for node0 and negative numbers for all the other nodes. As a result, all the above results are generated with only node0 doing all the processing. In order to show the trully distributed match results, I reversed back the k-means to have features partitioned to different nodes for QuickMatch. Currently, 3 nodes and 3 quickmatch nodes are initiated, with each pair of nodes representing a robot (therefore a total of 3 robots). The results are shown in this video: https://drive.google.com/open?id=15jJ97EmTyEOgKRVhlUpxcqnZzmVeug6p The same 6 images are repeated 3 times. During each repetition, the matches done for one specific pair of nodes (one robot) will be shown. It can be seen that the matches have been distributed across all nodes. Part 5: DocumentationDocumentation has been created here:
https://docs.google.com/document/d/1KD0Jc04j5ioy37Hnn30I92voBEUOVhij1nFr4NVViA4/edit?usp=sharing I am currently working on it. The goal is to finish all the documentations by next week. Part I: Technical difficulty connecting via TeamviewerCould not connect to lab computer via TeamViewer multiple times this week, but it is eventually fixed with Zach by following instructions on this page: https://www.thewindowsclub.com/teamviewer-stuck-on-initializing-display-parameters Part II: DebuggingAs suggested by Professor Tron, the k-means centers were manually set to the mean vector of all features for node0, and set to negative values for all the other nodes. During debugging, it has been verified that all the features would go to node0 so that I could compare my matching result to the result of the centralized version. Bug 1: After numerous print statements, I found that the bandwidth calculated in 'calc_density' function is incorrect. The function was outputting [0 1 2 3 4 ... 2999] instead of the correct bandwidth. When implementing the function, I changed some code to deal with another error I encountered, and I forgot to change them back after the previous debugging. After I changed the code back to match the centralized version, the function outputted the correct bandwidth. Bug 2: In order to calculate matches, we have to keep track of which image a particular feature belongs to. There was an mistake in the implementation: I was keeping track of which node a feature belongs to, instead of which image. This bug resulted in all the features belong to the same cluster in the 'break_merge_tree' function, since all the features belong to node0 in my debugging process. After correction, all the image numbers from 0 to 5 appeared (since there are 6 images) in 'break_merge_trees". Bug 3: This mistake is similar to bug 2. In the 'features_to_Dmatch' function, I compared indices with the node numbers instead of image numbers for each feature. It took me a long time to find it, but after I corrected it, the number of matches the algorithm found is exactly the same as the number of matches the centralized algorithms found (Figure 1 & 2).
Suspected Bug 4: (This is unresolved! Help!) After correcting bug 3, we can see that our matches are now correct. However, the matches drawn in the images do not look the same as ones in the centralized version (Figure 3 & 4). I believe this is due to 'quickmatch_node.py' re-calculating keypoints of the images for graphing. In the centralized version, the keypoints were calculated during feature extraction, and the same keypoints were used for graphing in the 'features_to_Dmatch' function. However, I was unable to use the same keypoints recorded in the feature extraction, because my feature extraction function and my 'features_to_Dmatch'/graphing function are in two different python files ('node.py' and 'quickmatch_node.py' respectively). As a result, I computed the keypoints again using the built-in `cv2.xfeatures2d.SIFT_create` function and `sift.detectAndCompute` function. I have discovered that the built-in feature extraction function does not output the same keypoints every time. For the centralized code, when I print out the keypoints, then results from one run would be different from results form another run. Although the keypoints were not used in match calculations, they were used for graphing. I tried to publish the keypoints obtained during feature extraction 'node.py', so 'quickmatch_node.py' can get the same keypoints for graphing. However, they are of the type <cv2.KeyPoint>, and ROS does not support publishing a cv2 object. I highly suspect that this is reason why the graphs are not showing up correctly even though the matches are already correct.  Figure 3: Correct graphing of distributed version on the same image.   Figure 4: Incorrect graphing results of the distributed version (above) and correct graphing results of the centralized version (below). Next steps:
Simple Distributed QuickMatch has been implemented (without points being contested). However, there are two problems with the current code. Problem 1: QuickMatch results are incorrectTThe distributed QuickMatch failed to find the matches even between the same images. This screenshot below shows the result of the centralized QuickMatch algorithm run on the same image:  This screenshot below shows the result of the current distributed QuickMatch run on the same image:  We can see that although the number of features are about the same, the distributed QuickMatch has not enough matches. The goal for next week is to investigate and try to make the result as close to the centralized version ans possible. My assumption is that there is a bug with my code. Part II: ROS constraintsMy distributed QuickMatch code crashes when running on big images. I initially used original images taken with my smart phone of 4032 x 3024 pixels (11MB), and the code would give an error saying insufficient memory. However, after I resized the images to 1/4 of the original size (1008 x 756 pixels), the error went away. I suspect that using multiple nodes in ROS to do image process at the same time has very high memory requirements.
Part 0: Connectivity IssueDue to BU closing down all the non-essential research labs, the lab computer has been turned off, and I was having difficulty accessing the lab computer via TeamViewer. Fortunately, Zack helped me restart the computer on Friday, so I could continue to work remotely. Part I: Bug FixThere was a bug in the code: the index out of bound error would appear sometimes when running the code, but not all the times (see screenshot below). 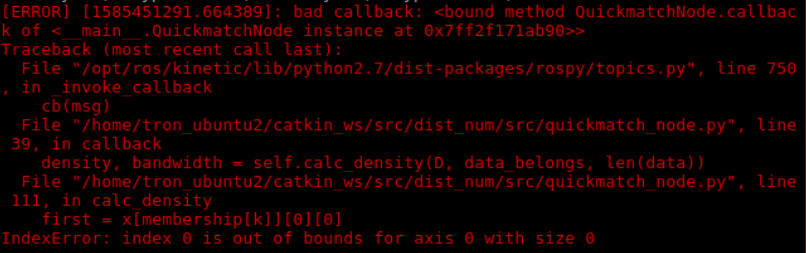 After hours of investigation, it turned out that the publisher (node.py) was sending empty features to the subscriber(quickmatch_node.py). Since the features are supposed to be published every second, I only checked the time intervals, not whether the feature collection is empty. The bug has been fixed. Now the publisher (node.py) would only publish features when the time interval has exceeded one second AND the features collection is not empty. The error did not occur again after running the code 10 times. Part II: Build Tree and Sorted EdgesThe build_kdtree and sort_edge_index functions have been integrated into the code. Both functions are working in the callback function of the quickmatch_node. No errors occur during runtime so far.
Next StepsThere are two versions of the break_merge_tree algorithm in the QuickMatch and NetMatch code bases. The next step is to investigate those two versions and integrate one of them into quickmatch_node.py.
Part I: Modifying K-means communicationPreviously, k-means partitions are computed by one node for the first image, and then written to the param.yaml file for every other node to read from. Since the parameter file only loads once when all the nodes are created, I am modifying the nodes to communicate k-means partition via a topic. Currently,
Part II: Calculating Feature DensitiesCurrently, the quickmatch node (different than the original node that initially publishes and receive features) is able to receive features (along with the corresponding agents they belong to) and calculate feature densities in the callback function. The callback function is triggered each time the subscriber receives information from the original node. The original node publishes features and feature members every second. It has been tested and verified that
Next Step:Next step is to keep implementing the quick match algorithm with the existing feature densities.
Part I: K-means testing on new dataBefore this week, I was using the existing 6 pictures to test k-means, and the number of collected features matched the number of extracted/published features. This week, I took 6 pictures of the same Clorox wipe box from different angles with my phone. For these new pictures, initially the total number of collected features by all nodes did not match the number of extracted/published features by all nodes. After hours of debugging, I found out that it had nothing to do with my code. It was purely due to the delay of the computation. If I put print statements after letting the nodes sleep for 2 seconds, the numbers will match again. One problem is that there's a delay from reading after writing the param files with the k-means labels. Currently the nodes read the labels written from the last time the script was run (always one round behind). Part II: Processing Node
Questions:
This week, k-means partitioning has been implemented and tested for 3 nodes. It works as follows:
Feedback from meeting:
|
Archives
May 2020
Categories |
 RSS Feed
RSS Feed
