Part 0: Connectivity IssueDue to BU closing down all the non-essential research labs, the lab computer has been turned off, and I was having difficulty accessing the lab computer via TeamViewer. Fortunately, Zack helped me restart the computer on Friday, so I could continue to work remotely. Part I: Bug FixThere was a bug in the code: the index out of bound error would appear sometimes when running the code, but not all the times (see screenshot below). 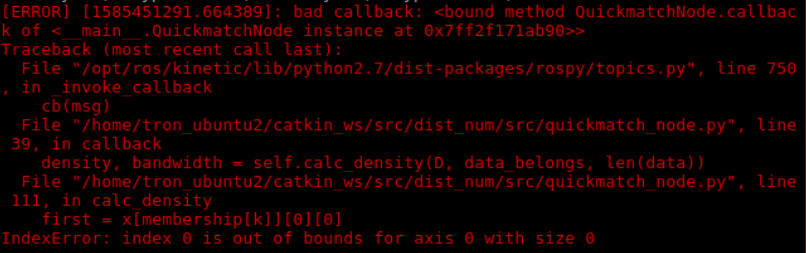 After hours of investigation, it turned out that the publisher (node.py) was sending empty features to the subscriber(quickmatch_node.py). Since the features are supposed to be published every second, I only checked the time intervals, not whether the feature collection is empty. The bug has been fixed. Now the publisher (node.py) would only publish features when the time interval has exceeded one second AND the features collection is not empty. The error did not occur again after running the code 10 times. Part II: Build Tree and Sorted EdgesThe build_kdtree and sort_edge_index functions have been integrated into the code. Both functions are working in the callback function of the quickmatch_node. No errors occur during runtime so far.
Next StepsThere are two versions of the break_merge_tree algorithm in the QuickMatch and NetMatch code bases. The next step is to investigate those two versions and integrate one of them into quickmatch_node.py.
0 Comments
Part I: Modifying K-means communicationPreviously, k-means partitions are computed by one node for the first image, and then written to the param.yaml file for every other node to read from. Since the parameter file only loads once when all the nodes are created, I am modifying the nodes to communicate k-means partition via a topic. Currently,
Part II: Calculating Feature DensitiesCurrently, the quickmatch node (different than the original node that initially publishes and receive features) is able to receive features (along with the corresponding agents they belong to) and calculate feature densities in the callback function. The callback function is triggered each time the subscriber receives information from the original node. The original node publishes features and feature members every second. It has been tested and verified that
Next Step:Next step is to keep implementing the quick match algorithm with the existing feature densities.
Part I: K-means testing on new dataBefore this week, I was using the existing 6 pictures to test k-means, and the number of collected features matched the number of extracted/published features. This week, I took 6 pictures of the same Clorox wipe box from different angles with my phone. For these new pictures, initially the total number of collected features by all nodes did not match the number of extracted/published features by all nodes. After hours of debugging, I found out that it had nothing to do with my code. It was purely due to the delay of the computation. If I put print statements after letting the nodes sleep for 2 seconds, the numbers will match again. One problem is that there's a delay from reading after writing the param files with the k-means labels. Currently the nodes read the labels written from the last time the script was run (always one round behind). Part II: Processing Node
Questions:
This week, k-means partitioning has been implemented and tested for 3 nodes. It works as follows:
Feedback from meeting:
This week's main task is to understand the current paper as well as the NetMatch algorithm. Since the basic code with random labels and nearest neighbors is working, it is time to start implementing QuickMatch distributedly on different nodes.
I spent a lot of time talking with Zack and reading about the current paper in publication. Here is a summary of Distributed QuickMatch (NetMatch) algorithm:
The next step would be to start implementing k-means partitioning and make sure everything still works the same. |
Archives
May 2020
Categories |
 RSS Feed
RSS Feed
